Few tasks expose the gap between a tidy keyword list and a publishable content plan quite like keyword clustering. You can export 2,000 queries from a research tool, stare at them in a spreadsheet, and still have no clear answer about which terms belong on the same page, which need their own URL, and which are quietly competing against content you already published.
Keyword Cupid aims to solve that with SERP-based clustering — a methodology that groups keywords by whether they actually share the same search results, rather than by whether they sound similar. This review examines what the tool does well, where it falls short, how its pricing structure works, and when a different approach — particularly one built on Google Search Console data — might serve your workflow better.
What Is Keyword Cupid?
Keyword Cupid is a keyword clustering tool that groups keywords by analyzing SERP overlap: if two queries consistently return the same ranking pages, the tool treats them as sharing search intent and places them in the same cluster. The underlying idea is that Google’s own ranking behavior is the most reliable signal for intent — more reliable than semantic similarity or manual tagging.
Who Keyword Cupid Is Built For
The tool targets SEO practitioners, content teams, and agencies who start their content planning with third-party keyword research. If your workflow begins in Ahrefs , Semrush , Google Keyword Planner , or a similar platform — producing a list of keywords with volume and difficulty estimates — Keyword Cupid is designed to be the next step: taking that raw list and organizing it into actionable clusters before you brief or draft a single page.
It fits naturally into workflows where keyword volume data is the primary planning input. Agencies managing keyword research at scale for multiple clients will find the batch processing approach useful. Solo consultants and small teams looking to reduce manual grouping time have the same appeal for the tool.
What Problem It Solves in Keyword Clustering
Without structured clustering, content teams face two common failure modes. The first is over-creation: writing separate pages for terms that actually share intent, which either wastes production resources or causes keyword cannibalization. The second is under-coverage: bundling distinct intent variants onto one page when Google is clearly serving different results for each.
Keyword Cupid addresses both by automating the grouping decision based on SERP behavior rather than gut feel or surface-level keyword similarity. “Best project management software” and “top project management tools” might look identical in meaning but return different SERP compositions — or they might return near-identical results and belong together. SERP-based clustering resolves that question empirically.
How It Differs from Generic Keyword Grouping Tools
Many free or basic grouping tools rely on n-gram matching or topic tags — clustering “project management software” with “project management app” because they share the root phrase. That approach is fast but shallow. Keyword Cupid’s SERP-analysis model is more computationally intensive, but it produces clusters that reflect real Google behavior rather than linguistic similarity alone.
How Keyword Cupid Works
SERP-Based Clustering and Search Intent Overlap
The core mechanism is SERP overlap analysis. Keyword Cupid pulls live search results for each keyword in your list, then measures how many of the same URLs appear across pairs of keyword results. A high overlap score suggests the keywords share user intent. A low score suggests they are likely informational vs. transactional variants — or simply target different subtopics that Google treats as distinct.
This approach has a meaningful advantage over pure semantic models: it captures intent at the query level rather than at the topic level. Two questions can be topically related but serve completely different user goals, and SERP data picks that up where word embeddings often do not.
Machine Learning and Confidence Scoring
Beyond raw overlap counts, Keyword Cupid applies machine learning to assign cluster confidence scores. These scores indicate how cleanly a keyword fits its assigned cluster — and flag terms where the clustering decision is ambiguous. This matters in practice because not every grouping will be obvious. A keyword that scores low confidence warrants a manual SERP check before you commit to a page structure built around it.
The confidence layer is one of the tool’s more operationally useful features: it surfaces the decisions you need to review rather than presenting every cluster as equally certain.
From Keyword List to Topical Map
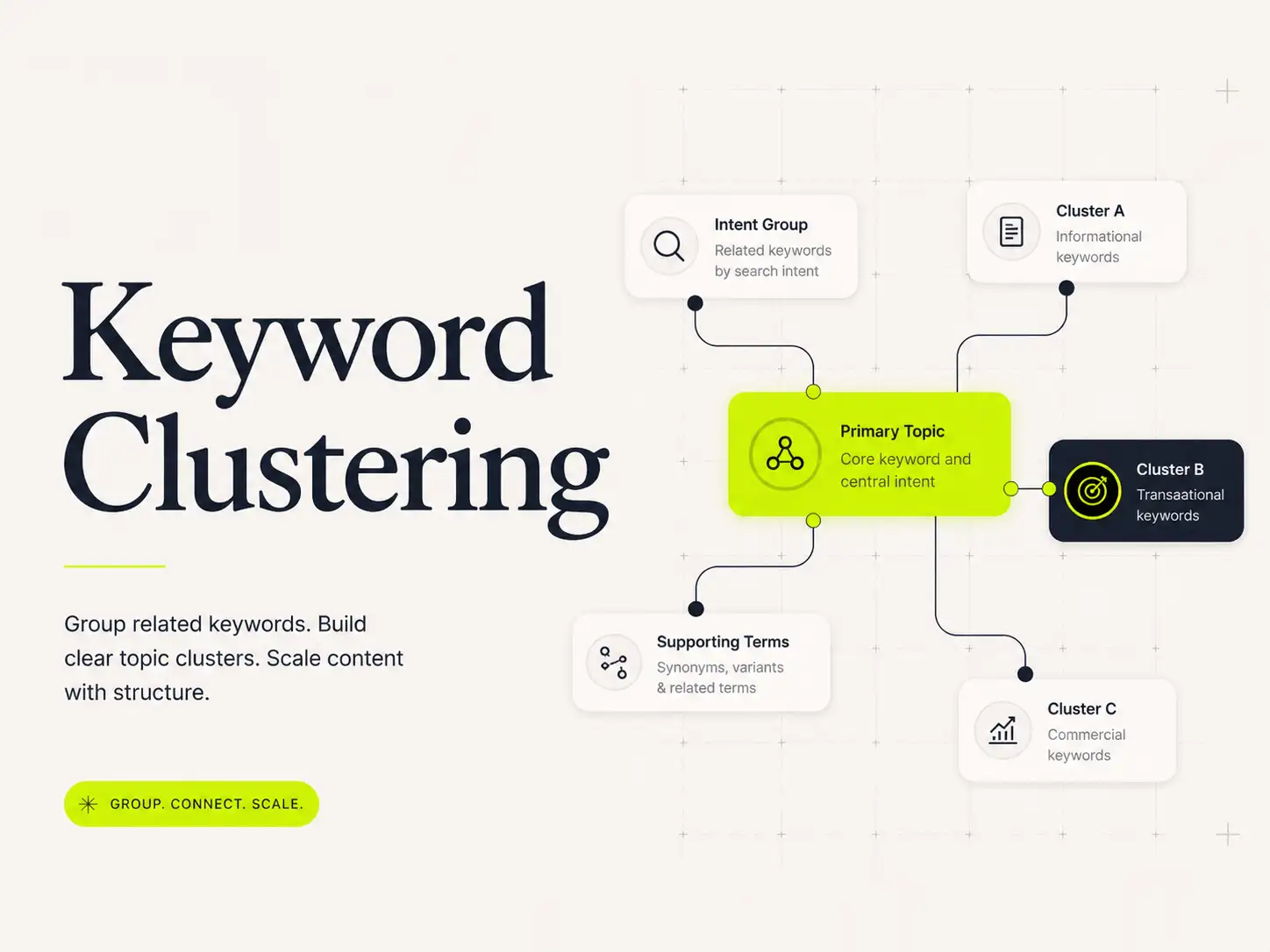
The workflow is fairly linear. You upload your keyword list — typically exported from a keyword research tool — and Keyword Cupid processes it into cluster groups. Each cluster is assigned a primary keyword (usually the highest-volume or highest-intent term) and a list of supporting variants. The output represents a draft topical map: one potential page per cluster, with each page targeting a specific intent segment.
From there, you can identify content gaps, spot clusters where you already have existing pages, and prioritize which clusters to build out first.
How Visual Mind Maps Help Content Planning
Keyword Cupid offers visual mind map outputs that display cluster relationships. For teams that plan content architecture in collaborative tools, this kind of visual representation helps communicate structure to writers, editors, and stakeholders who may not read a spreadsheet the same way an SEO does. Mind maps make it easier to see how supporting clusters relate to broader pillar topics and how deep the topical coverage needs to go before you can credibly compete for head terms.
Key Features to Evaluate Before Using Keyword Cupid
Keyword Clustering and Grouping
This is the product’s core capability. The SERP-based clustering engine processes keyword lists of varying sizes and returns organized cluster groups with supporting metadata. Evaluation criteria worth applying before committing: how the tool handles very large keyword sets, how it manages duplicate intent variants, and whether you can adjust sensitivity thresholds to control cluster granularity.
Coarser clusters reduce page count but risk lumping distinct intents together. Finer clusters increase page count but can create an unmanageable backlog of thin-coverage content. The right setting depends on your site’s existing authority and content production capacity.
Content Silo and Topical Authority Planning
Once clusters are defined, Keyword Cupid’s output maps naturally to a content silo structure: pillar pages covering broad topics, supported by cluster pages targeting narrower intent variants. Building out complete silos is widely understood to reinforce topical authority — the signal to Google that your site is a reliable source on a subject, not just a collection of loosely related pages. Google’s helpful content guidance is a useful reference point here because it emphasizes people-first coverage, original value, and subject-matter usefulness rather than publishing pages only to capture keyword variations.
The practical question is whether Keyword Cupid’s clustering output matches your site’s actual domain authority. A site with limited backlink profile typically can’t compete on every cluster simultaneously. Prioritization logic matters as much as the cluster map itself.
SERP Spy and On-Page Recommendations
Keyword Cupid includes features that let you analyze what’s currently ranking for your target clusters — who is ranking, what type of content they’ve published, and what on-page signals appear common across top results. This competitive analysis layer helps inform content briefing: understanding what format performs (list, guide, comparison, tool review) and what depth is required to be competitive.
On-page recommendations translate SERP analysis into guidance about headings, word count ranges, and related topics to cover. This shortens the gap between cluster identification and a usable content brief.
Cluster Confidence and Manual Review
As mentioned earlier, confidence scoring surfaces the clusters most likely to need a second opinion. Any production workflow should include a manual SERP review step for low-confidence clusters before publishing. Treating every cluster output as correct without verification is one of the more common ways keyword clustering adds noise rather than clarity.
It’s worth building a review step into your standard operating procedure, especially for competitive terms where the wrong intent assumption can mean a published page that never ranks.
Export Options for Editorial Workflows
Keyword Cupid allows you to export cluster data — typically in CSV or Excel-compatible formats — for use in editorial planning tools, project management systems, or content calendars. The practical quality of this export matters: column structure, metadata included, and whether the output integrates cleanly into your existing systems. Verify before purchasing whether the export format matches what your team actually needs.
Keyword Cupid Pricing: What to Check Before You Buy
Why Pricing Should Be Verified on the Official Site
Keyword Cupid’s pricing structure has changed over time, and third-party reviews — including this one — may lag behind current plans. Always check the official Keyword Cupid pricing page for current pricing before making a purchase decision. This review will not quote specific figures that could be out of date.
Questions to Ask About Credits, Limits, and Projects
Before purchasing any tier, clarify: How are keywords counted — by upload size or by SERP queries generated? Are credits consumed per keyword, per cluster run, or per project? What is the maximum keyword volume per processing job? Are there limits on the number of concurrent projects or active clusters?
The answers affect total cost materially, especially for agencies running multiple client projects.
When Pay-Per-Use Clustering May Be Better Than Subscriptions
If your team runs keyword clustering in batches — typically at project start or during quarterly content planning — a pay-per-use or credit-based model may have a lower total cost than a monthly subscription. Subscriptions make more sense for teams clustering continuously or refreshing keyword data at regular intervals.
What Agencies Should Check Before Scaling Client Workflows
Agencies should verify: Does the pricing support multiple client workspaces or projects? Are there limits on how many projects can be active simultaneously? What happens to project data when a client engagement ends — is there export access? These operational questions matter as much as headline pricing.
Pros and Cons of Keyword Cupid
Where Keyword Cupid Is Strong
The SERP-based clustering methodology is genuinely more rigorous than n-gram matching or topic-label grouping. For teams starting with third-party keyword data, Keyword Cupid reduces the manual time required to organize a large keyword list into a workable content plan. The confidence scoring and visual mind map outputs add practical value for teams that need to communicate cluster structure to non-technical stakeholders.
The on-page recommendation layer brings the tool closer to a lightweight brief — useful for smaller teams that don’t have a dedicated content strategist.
Where Teams May Need Extra Tools
Keyword Cupid does not replace a full content brief workflow. SERP analysis tells you what exists; it doesn’t fully account for what your specific audience needs or how your brand should position within a topic. Teams will still need to layer in audience research, competitive differentiation, and tone guidance before handing a brief to a writer.
The tool also doesn’t natively connect to Google Analytics or Google Search Console . That means the clusters it produces are built from third-party keyword data — search volume estimates, difficulty scores — rather than from actual performance signals on your site.
Potential Workflow Gaps for GSC-Driven SEO Teams
If your team already uses Google Search Console as a primary planning input — reviewing which queries are gaining impressions, which pages are losing position, which queries are surfacing for pages they shouldn’t — then Keyword Cupid sits outside that workflow rather than inside it. The clusters it builds are disconnected from what Google is already telling you about your site.
This creates a reconciliation step: after Keyword Cupid generates clusters from a third-party list, someone still needs to cross-reference those clusters with existing GSC data to avoid doubling down on clusters your site is already winning, or building new pages that cannibalize existing rankings.
How to Evaluate Output Quality Before Publishing Content
Before letting any cluster output drive content production, verify a representative sample against live SERPs. Pick ten to twenty clusters across different confidence levels, run the primary keyword in an incognito browser, and assess whether the results actually match the implied intent of the cluster. Review whether your existing site pages already rank for any of the cluster’s keywords — if so, a new page is probably the wrong decision.
This validation step is not optional if quality matters. Cluster outputs are a starting point, not a final answer.
Keyword Cupid vs GSC-Native Keyword Clustering
Third-Party Keyword Lists vs First-Party Performance Data
Keyword Cupid’s input is a list you build from third-party tools. That data reflects estimated search volume and competitive difficulty — useful signals, but approximations. Google’s actual query data, surfaced through Search Console, tells you what people are already searching for when they find (or almost find) your specific site. These two data sources answer different questions.
Third-party data is useful for discovery: finding keywords your site doesn’t yet rank for. GSC data is essential for optimization: understanding what you’re already competing for, where you’re leaking impressions without clicks, and which existing pages are drifting or cannibalizing each other.
Why Search Console Data Matters After Content Is Live
Once content is published, GSC data becomes the most accurate planning input available. Click-through rates, average position, impression trends, and query-to-page alignment all reflect real user behavior and real Google indexing decisions. Google’s Search performance report documentation explains how clicks, impressions, CTR, and average position are measured, which is why this data is so valuable for post-publication SEO decisions. Third-party tools can estimate search volume but cannot replicate this post-publication signal fidelity.
For teams with established content libraries — say, 50+ published posts — GSC-driven analysis often surfaces more high-value opportunities than new keyword research alone: pages that rank on page two for multiple queries and need a targeted refresh, or existing pages that are inadvertently competing against each other.
How GSC-Native Clustering Can Reduce Cannibalization
Keyword cannibalization — where two or more pages on your site compete for the same query — is difficult to detect from a third-party keyword list because the list doesn’t know your site structure. A GSC-native clustering approach solves this by mapping every cluster to the pages that are actually ranking for its keywords. When the same keyword appears in the top queries for two different pages, the system flags a potential cannibalization issue before you decide to create a third page.
This is a structural advantage over tools that work from keyword lists without site context.
When to Combine Keyword Cupid with Google Search Console
The two approaches are complementary when used in the right sequence. Keyword Cupid’s value is highest at the start of a new content initiative — when you’re building a cluster map for a topic area your site doesn’t yet cover. GSC data becomes the primary input for managing and optimizing content once pages are live.
A combined workflow: use Keyword Cupid to map new cluster opportunities from a keyword research export, then validate those clusters against Search Console to confirm they don’t overlap with existing rankings. After content is published, shift to a GSC-native tool for monitoring, refreshing, and expanding. Dango’s Search Console-native SEO platform is designed specifically for this second phase — connecting directly to your GSC data to surface content opportunities, map clusters to existing pages, and automate internal linking based on your site’s actual performance.
Keyword Cupid Alternatives to Compare
For teams evaluating their options, Keyword Cupid competes in a crowded space. The right choice depends on where your data lives, how your team works, and what you need the tool to do beyond grouping keywords. For a broader view of the category, our roundup of the best keyword clustering tools covers the full landscape, from free options to enterprise-grade platforms.
Dango for Search Console-Native Clustering and Content Workflows
Dango is the option built for teams where GSC data is the primary planning input. Rather than uploading a keyword list from a third-party tool, Dango pulls live query data from your connected Search Console account and clusters it against your existing pages. It detects cannibalization at the cluster level, maps opportunities to new or existing URLs, and generates content briefs with internal linking built in.
The core difference is data source: Dango works with what Google has already observed about your site, not with estimated search volumes. For teams with meaningful organic traffic and an existing content library, this produces more actionable prioritization because the decisions are grounded in real performance signals rather than keyword planner estimates.
Keyword Insights for Keyword Clustering and Content Planning
Keyword Insights is one of the closest feature comparisons to Keyword Cupid. It uses SERP-based clustering with a similar intent-overlap methodology, adds NLP processing for refinement, and includes a content brief output layer. Teams that want a dedicated clustering tool with slightly more robust brief features often compare these two directly.
Key evaluation criteria: clustering speed at scale, brief depth, and pricing relative to your keyword volumes. Both tools operate from uploaded keyword lists rather than GSC data, so the same reconciliation workflow applies.
Semrush and Ahrefs for Broader SEO Suites
Semrush and Ahrefs both include keyword grouping or clustering functionality as part of their broader platform capabilities. The advantage is consolidation — if you’re already paying for one of these platforms, you may not need a separate clustering tool. The tradeoff is that their clustering features are typically less specialized than standalone tools, and neither integrates natively with Google Search Console as a planning input.
For teams that need clustering as one part of a full SEO toolkit including backlink analysis, rank tracking, and site auditing, these remain the dominant choices. For teams whose core need is clustering specifically, a dedicated tool usually offers more control.
Surfer SEO and Clearscope for Content Optimization
Surfer SEO and Clearscope occupy a different position in the stack. Both are primarily content optimization tools — they analyze what’s ranking for a given query and provide on-page recommendations for structure, word count, and semantic coverage. Surfer has expanded into content planning and cluster mapping, but the primary value proposition for both remains optimizing a specific piece of content after the cluster decision is already made.
These tools complement a clustering workflow rather than replacing it. If content quality and semantic depth are the gaps in your current process, either tool may be more urgent than a better clustering tool.
How to Choose Based on Team Size, Data Source, and Workflow
The right tool follows directly from where your content planning starts. If you start with third-party keyword research and need to organize large keyword sets quickly, Keyword Cupid or Keyword Insights are natural candidates. If you start from your existing site’s GSC performance data and need to build on what’s already working, a GSC-native platform like Dango is better aligned. If you need a complete SEO suite rather than a specialized tool, Semrush or Ahrefs may be the more efficient investment.
Reviewing the broader category of AI SEO tools for content workflows can help teams understand where each tool fits in the full content production stack before committing to a purchase.
Recommended Workflow for Using Keyword Cupid in a Content Strategy
Start With a Clean Keyword List
The quality of your cluster output depends directly on the quality of your input. Before uploading to Keyword Cupid, remove obvious duplicates, irrelevant tangents, and branded navigational queries that don’t belong in your content plan. Deduplicate at the semantic level, not just exact-match — “email marketing tool” and “email marketing tools” don’t both need to be in your list. A cleaner input produces more accurate clusters and reduces noise in the confidence scoring.
Review Clusters Against Real SERPs
After the clustering run completes, validate a representative sample manually. Open the top-ranked pages for each primary keyword in a private browsing window. Assess whether the content type, format, and depth match your planned page. If the SERP is dominated by tools and the cluster output suggests a how-to guide, there’s a format mismatch that no amount of on-page optimization will easily overcome.
Pay particular attention to low-confidence clusters. These are the groupings where the SERP data was ambiguous — and they’re the ones most likely to result in a published page targeting the wrong intent.
Map Clusters to Existing Pages Before Creating New Ones
Before building a new page for any cluster, check whether your site already has a page that covers the cluster’s primary keyword. This step is often skipped, but skipping it is how cannibalization happens. Google’s SEO Starter Guide recommends organizing content so users and search engines can understand related pages clearly, and cluster-to-URL mapping is one practical way to do that. Export your existing page URLs and their primary topics, then cross-reference them against the Keyword Cupid cluster output.
Where there’s overlap, the decision is a refresh or expansion of an existing page, not a net-new URL. New pages should only be created for genuinely uncovered clusters.
Use GSC Data to Validate Priorities
Keyword Cupid’s cluster priorities are based on search volume and difficulty estimates. These are useful signals, but they don’t account for your site’s existing authority in specific topic areas. Cross-referencing your cluster map against Google Search Console data often reshuffles priorities: clusters where your site already appears on page two or three may be more achievable in the near term than clusters where you have no existing foothold.
GSC data also flags existing pages with strong impression-to-click ratios that could benefit from updated content before you build new pages at all.
Turn Clusters Into Briefs, Internal Links, and Refresh Tasks
A cluster map only creates value when it drives production. For each prioritized cluster, the output should translate into one of three actions: a new content brief, a refresh brief for an existing page, or a task to improve internal linking between related pages.
Understanding what that production workflow looks like in practice is important before setting up a cluster-to-content pipeline. Our guide on SEO content writer workflow covers how clusters become briefs, briefs become optimized drafts, and drafts get integrated with internal link architecture — the full sequence from keyword data to published, interlinked content.
Final Verdict: Is Keyword Cupid Worth It?
Best-Fit Use Cases
Keyword Cupid earns its keep in specific contexts. Teams doing large-volume keyword research who need to reduce a 1,500-keyword list to a manageable cluster map before any content production begins will get real time savings from the automation. Agencies building out keyword architecture for new client sites or new topic areas — where there’s no existing content or GSC history to work from — benefit from the SERP-based approach.
The tool is also strong for content audits where you’re mapping existing content against a fresh keyword clustering run to identify gaps and redundancies in your current coverage.
When to Choose a Different Tool
If your site has meaningful organic traffic and an existing content library, the most valuable clustering and prioritization decisions will come from your own Search Console data, not from third-party volume estimates. In that case, a GSC-native workflow captures opportunities that Keyword Cupid cannot surface — because it doesn’t have access to your actual performance signals.
Keyword Cupid also isn’t the right primary tool if your core content challenge is quality and optimization rather than organization. For sites where ranking problems come from thin content, poor on-page structure, or competitive gaps in depth, content optimization tools like Surfer SEO or Clearscope address a more fundamental problem.
Decision Checklist for SEO Teams and Agencies
Before purchasing Keyword Cupid, work through these questions:
- Is the primary bottleneck in your workflow actually keyword organization, or is it something upstream (research) or downstream (content quality)?
- Does your team start from third-party keyword lists, or from Google Search Console data?
- Do you have existing content that needs to be mapped before new pages are created?
- Does the pricing structure work for your project cadence — batch clustering or continuous use?
- Are there existing tools in your stack that already cluster keywords, even if less precisely?
- Will you have a validation step before clusters drive content production?
If the answers point toward a third-party-list-first workflow with genuine organizational bottlenecks, Keyword Cupid is worth evaluating seriously. If the answers point toward GSC-first prioritization on an established site, a tool like Dango’s Search Console-native SEO platform may solve the actual problem more directly.
Frequently Asked Questions
Is Keyword Cupid good for beginners?
Keyword Cupid can be used by beginners, but it’s best understood by someone who already knows the basics of keyword research and content planning. The tool assumes you can supply a keyword list and interpret cluster outputs — and that interpretation requires some SEO judgment, especially when reviewing low-confidence clusters or deciding between creating a new page versus refreshing an existing one.
Does Keyword Cupid use Google Search Console data?
No. Keyword Cupid works from keyword lists you upload, typically exported from third-party research tools like Ahrefs, Semrush, or Google Keyword Planner. It does not connect to Google Search Console and does not analyze your site’s actual query performance data. That gap is worth accounting for in any workflow where existing site rankings are relevant to content decisions.
Can Keyword Cupid help prevent keyword cannibalization?
Keyword Cupid can reduce cannibalization during the planning phase by grouping keywords that share intent — reducing the likelihood you’d create two separate pages for the same search query. However, because it doesn’t know your existing site structure or Search Console data, it cannot detect cannibalization that’s already happening across your published pages. That requires a site-aware tool that can cross-reference cluster data against existing URLs and rankings.
How accurate is SERP-based keyword clustering?
SERP-based clustering is generally more accurate than n-gram or topic-label matching because it uses actual ranking behavior as the grouping signal. However, accuracy varies with SERP volatility, keyword query volume (sparse data for low-volume terms reduces cluster reliability), and the time delay between when SERPs were sampled and when you’re using the cluster output. High-confidence clusters are typically reliable; low-confidence clusters always warrant manual verification.
Do you still need a content brief tool with Keyword Cupid?
Yes, for most workflows. Keyword Cupid’s on-page recommendations provide useful context, but a cluster output is not a content brief. A complete brief includes competitive positioning, audience and tone guidance, internal linking structure, word count targets, and heading outlines that are specific to your site — not just what’s generically present in the SERP. Teams serious about content quality will use Keyword Cupid’s output as an input to a brief rather than as a brief itself.
What is the best Keyword Cupid alternative for SaaS SEO teams?
For SaaS teams with existing organic traffic, the most useful alternative is typically a GSC-native platform that can cluster real query data, map it to existing pages, and identify cannibalization or decay in the current content library. Dango is built specifically for this use case. For teams early in their SEO program without significant GSC history, Keyword Insights offers a comparable SERP-based clustering approach with slightly different brief features that some teams prefer.
Can agencies use Keyword Cupid for multiple client sites?
Yes, but verify the pricing structure carefully before scaling. Some plans limit the number of active projects or the total keyword volume across projects, which affects the per-client cost at scale. Agencies should also confirm how project data is organized within the tool — whether client projects can be cleanly isolated — and what the export options look like when a client engagement ends.
Should you cluster keywords before or after publishing content?
Both. Clustering before publishing is the standard use case — you organize a keyword list into a content map and build pages based on that structure. Clustering after publishing is equally valuable: running your existing content library against current SERP data often reveals that pages have drifted into unintended intent territory, that two pages are competing for the same cluster, or that cluster gaps exist in topics you thought were well covered. Post-publication clustering is one of the most underused applications of the methodology.